


Sự gia tăng nhanh chóng của các bài báo khoa học kém chất lượng, bao gồm cả những công trình giả mạo được tạo ra bởi trí tuệ nhân tạo (AI), đang đặt ra một thách thức mang tính sống còn đối với cách thức tổng hợp bằng chứng truyền thống. Tuy nhiên, nếu được áp dụng đúng hướng, AI cũng có thể trở thành một phần của giải pháp.
Trong nhiều thập kỷ, các phương pháp tổng hợp bằng chứng (evidence synthesis) đã giúp nâng cao đáng kể chất lượng của nghiên cứu y học và nhiều lĩnh vực khác. Việc hệ thống hóa và kết hợp kết quả từ nhiều nghiên cứu thành các bản tổng quan toàn diện cho phép các nhà nghiên cứu và hoạch định chính sách rút ra những kết luận chắc chắn từ kho tri thức toàn cầu. AI hiện hứa hẹn rút ngắn đáng kể một số khâu trong quy trình này, chẳng hạn như tìm kiếm, sàng lọc tài liệu hay phát hiện các nghiên cứu đáng ngờ. Tuy vậy, một số ứng dụng AI hiện nay vẫn chưa đủ mạnh để đảm bảo tính tin cậy và khả năng thích ứng của quá trình tổng hợp bằng chứng, đặc biệt trong bối cảnh AI cũng được dùng để tạo ra các bài báo giả mạo, làm gia tăng nguy cơ khủng hoảng toàn diện trong lĩnh vực này.
Điều cần thiết không chỉ là cải thiện quy trình hiện có, mà là chuyển sang một cách tiếp cận hoàn toàn mới: linh hoạt phản ứng trước những biến động nhanh chóng của hệ thống xuất bản khoa học, kể cả khi bài báo bị rút lại hay chỉnh sửa. Giải pháp được đề xuất là xây dựng một mạng lưới cơ sở dữ liệu bằng chứng “sống”, liên tục được cập nhật và quản lý bởi nhiều tổ chức độc lập, trong đó AI đóng vai trò hỗ trợ thu thập, tổ chức và sàng lọc thông tin. Mỗi cơ sở dữ liệu sẽ bao quát một lĩnh vực hoặc chủ đề rộng, trở thành nền tảng để thực hiện nhanh chóng và đáng tin cậy nhiều bản tổng quan có phạm vi cụ thể hơn.
Hạn chế của tổng quan hệ thống truyền thống
Hiện nay, tổng quan hệ thống được coi là “chuẩn vàng” trong việc tổng hợp bằng chứng. Quy trình này đòi hỏi sự toàn diện, chặt chẽ, minh bạch và khách quan, nhằm bao quát tối đa các bằng chứng chất lượng cao và giảm thiểu sai lệch. Các tiêu chí lựa chọn, chiến lược tìm kiếm, nguồn dữ liệu và xung đột lợi ích đều được công khai, đồng thời nhiều tác giả cùng tham gia rà soát để hạn chế thiên lệch cá nhân.
Tuy nhiên, cái giá phải trả cho chất lượng này là nguồn lực khổng lồ. Một số tổng quan Cochrane, vốn được xem là tiêu chuẩn vàng trong lĩnh vực y tế, có chi phí trên 140.000 USD và mất hơn hai năm để hoàn thành. Trong khi đó, khối lượng công bố khoa học đã tăng gấp đôi mỗi 14 năm kể từ 1952, khiến các nhóm tác giả ngày càng khó theo kịp. Điều này khiến các nhóm nghiên cứu khó theo kịp, đặc biệt khi mỗi người truy cập cơ sở dữ liệu khác nhau, và cơ sở dữ liệu thì luôn được cập nhật liên tục.
Tính tái lập cũng là vấn đề nan giải. Chỉ khoảng 1% tổng quan hệ thống mô tả chiến lược tìm kiếm đủ rõ ràng để người khác có thể lặp lại y nguyên. Nhiều tổng quan vẫn vô tình trích dẫn những nghiên cứu đã bị rút lại vì sai sót, vi phạm đạo đức hoặc gian lận.
Khi AI trở thành “con dao hai lưỡi”
AI có thể hỗ trợ sàng lọc nhanh hơn, phân tích sâu hơn và tiếp cận nhiều ngôn ngữ hơn. Nhưng mặt khác, sự bùng nổ của các mô hình ngôn ngữ lớn (LLMs) cũng mở ra nguy cơ tràn ngập các bài báo giả mạo. Chẳng hạn, một bài báo do AI Scientist (công cụ do Sakana AI ở Tokyo phát triển) tạo ra đã được chấp nhận tại hội thảo thuộc một hội nghị AI lớn mà không ai phát hiện đó là sản phẩm của máy móc.
Một nghiên cứu sơ bộ trên arXiv ước tính rằng ít nhất 10% các phần tóm tắt của bài báo (Abstract) trên PubMed năm 2024 có sự tham gia của LLMs. Ranh giới giữa việc dùng AI để cải thiện ngôn ngữ và để tạo ra bài báo giả mạo rất khó xác định. Việc tạo ra một bản thảo giả đã trở nên dễ dàng hơn bao giờ hết, nhằm phục vụ cho các mục đích từ thao túng kết quả đến phục vụ lợi ích cá nhân.
Sự khó khăn trong phân biệt giữa hỗ trợ hợp pháp và lạm dụng để tạo nội dung giả khiến AI có thể trở thành chất xúc tác cho “lò bán bài báo”, vốn chuyên sản xuất công trình giả để bán cho những người muốn thăng tiến học thuật. Với AI, quá trình này thậm chí có thể diễn ra trong vài phút và hầu như không tốn chi phí.
Các biện pháp ứng phó hiện tại
Một số tổ chức như Cochrane hay Campbell Collaboration đã đưa ra hướng dẫn nhằm nhận diện và loại bỏ nghiên cứu bị rút khỏi các bản tổng quan, như:
- Đối chiếu với cơ sở dữ liệu Retraction Watch để xác định các bài bị rút.
- Sử dụng CENTRAL – kho lưu trữ thử nghiệm lâm sàng có đánh dấu nghiên cứu bị rút.
- Nếu tổng quan đã xuất bản có trích dẫn bài bị rút, cần tính toán lại kết quả, gắn cảnh báo hoặc rút bản cũ và thay thế bằng phiên bản cập nhật.
Tuy nhiên, thực tế cho thấy các bước này hiếm khi được thực hiện đầy đủ, chủ yếu do hạn chế về thời gian và nguồn lực. Một nghiên cứu đã chỉ ra rằng, trong số các tổng quan hệ thống về thuốc được thử nghiệm lâm sàng, có đến 89% vẫn tiếp tục trích dẫn các nghiên cứu đã bị rút, dù các tác giả đã được thông báo từ một năm trước.
Mô hình “cơ sở dữ liệu bằng chứng sống” và vai trò của AI
Số lượng bài báo khoa học – cả hợp pháp lẫn giả mạo – đang tăng với tốc độ chưa từng có, khiến việc theo dõi, đánh giá và cập nhật thông tin chính xác trở thành thách thức lớn đối với cộng đồng nghiên cứu (xem thêm mục “More papers, more retractions”)
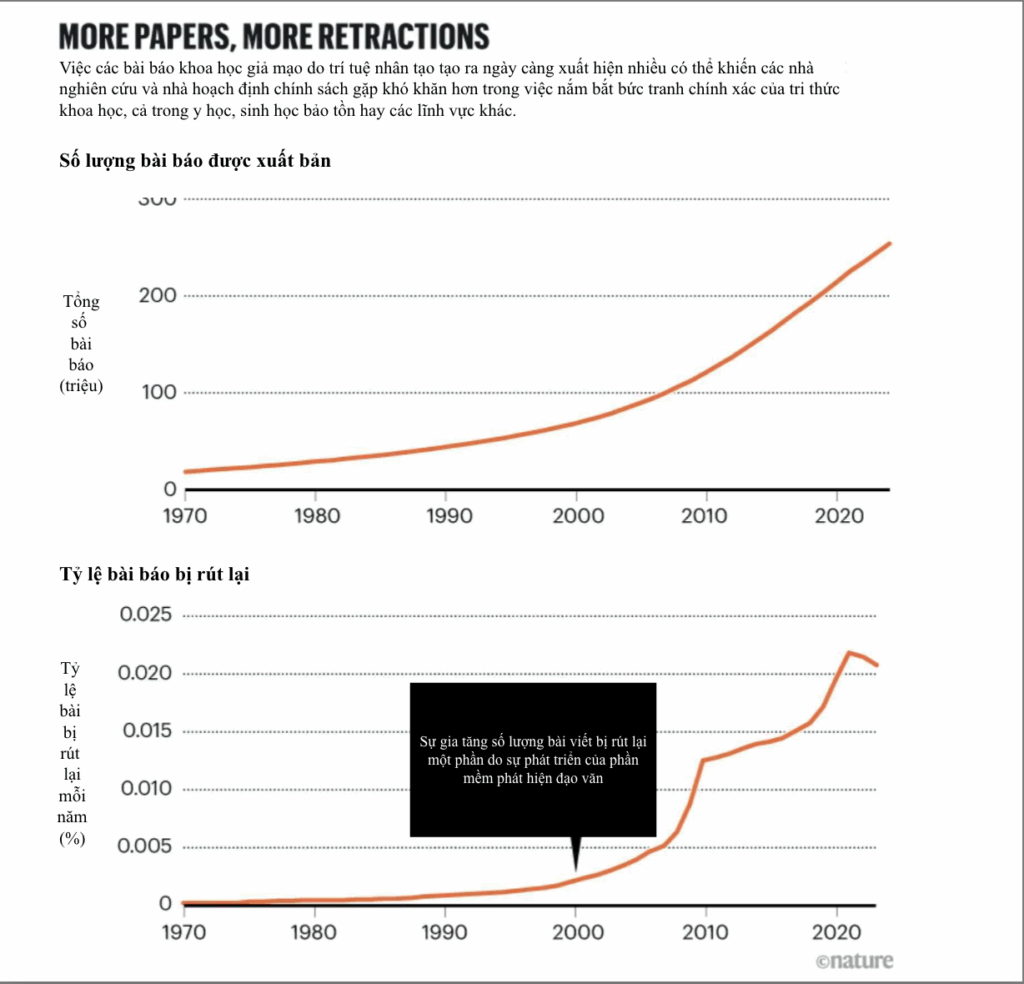
Trong bối cảnh này, cần một hệ thống có khả năng tự động, nhanh chóng và trên quy mô lớn loại bỏ những nghiên cứu giả mạo hoặc chứa sai sót nghiêm trọng khỏi cơ sở dữ liệu khoa học.
Kinh nghiệm từ dự án Conservation Evidence tại Đại học Cambridge gợi ý một hướng đi khả thi. Dự án này xây dựng cơ sở dữ liệu về hiệu quả các biện pháp bảo tồn đa dạng sinh học, được cập nhật định kỳ và sàng lọc hơn 1,2 triệu bài báo bằng 17 ngôn ngữ khác nhau. Phiên bản mở rộng, dự án Metadataset còn trích xuất dữ liệu định lượng để phục vụ phân tích tổng hợp tùy biến. Cách làm này cho phép trả lời các câu hỏi nghiên cứu trong vài giờ, thay vì nhiều tháng hoặc năm.
Ý tưởng là mở rộng nguyên mẫu này thành mạng lưới toàn cầu các cơ sở dữ liệu bằng chứng sống, nơi AI liên tục quét, sàng lọc, trích xuất dữ liệu, loại bỏ nghiên cứu bị rút và thậm chí phát hiện bài giả chưa bị thu hồi. Các cơ sở dữ liệu sẽ được nhân bản tại nhiều tổ chức độc lập để tránh rủi ro chính trị hay kỹ thuật, đồng thời mỗi tổng quan sẽ gắn với một mã định danh phản ánh trạng thái dữ liệu tại thời điểm thực hiện, giúp tăng tính tái lập.
AI có thể giúp giảm đáng kể chi phí xây dựng ban đầu, hỗ trợ xử lý đa ngữ và mở rộng ứng dụng sang nhiều lĩnh vực ngoài bảo tồn. Dù vẫn tồn tại thách thức như tái lập kết quả khi AI liên tục cập nhật, cách tiếp cận này hứa hẹn đáp ứng nhu cầu ngày càng cấp bách về một hệ thống tổng hợp bằng chứng minh bạch, cập nhật nhanh và đáng tin cậy.
Lược dịch từ Nature










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}